配置SSH无密码登陆
1 | 1.ssh-keygen -t rsa //然后一路回车 |
安装JDK
安装Hadoop
1.官网下载hadoop压缩包(这里是hadoop-2.7.3.tar.gz)
2.解压1
tar -zxvf hadoop-2.7.3.tar.gz
3.修改hadoop配置文件1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61cd /opt/hadoop-2.7.3/etc/hadoop
(1).配置hadoop-env.sh
# The java implementation to use.
#export JAVA_HOME=${JAVA_HOME}
export JAVA_HOME=/usr/java/jdk1.8.0_121(自己的jdk路径)
(2).//修改配置core-site.xml
vi core-site.xml
<configuration>
<!--配置hdfs的namenode(老大)的地址-->
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
<description>HDFS的URI,文件系统://namenode标识:端口号</description>
</property>
<!--配置hadoop运行时产生数据的存储目录,不是临时的数据-->
<property>
<name>hadoop.tmp.dir</name>
<value>/hadoop/tmp</value>
<description>namenode上本地的hadoop临时文件夹</description>
</property>
</configuration>
(3).修改配置hdfs-site.xml
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
<description>副本个数,配置默认是3,应小于datanode机器数量</description>
</property>
</configuration>
(4).修改mapred-site.xml
mv mapred-site.xml.template mapred-site.xml
vi mapred-site.xml
<configuration>
<!--指定mapreduce运行在yarn模型上-->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
(5).配置yarn-site.xml
<configuration>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>127.0.0.1</value>
</property>
<!--mapreduce执行shuffle时获取数据的方式-->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
4.启动hadoop
(1)格式化namenode1
bin/hdfs namenode -format
(2)启动NameNode 和 DataNode 守护进程1
sbin/start-dfs.sh
(3)启动ResourceManager 和 NodeManager 守护进程1
sbin/start-yarn.sh
(4)jps命令查看进程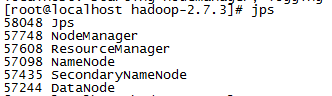
访问
127.0.0.1:50070
127.0.0.1:8088
如果可以访问表示配置成功